Générer des données bidons en SQL
En programmation, il est souvent utile d'être capable de générer des données non persistantes (i.e. non sauvegardées physiquement) afin de réaliser un traitement en mémoire. Par exemple, nous avons une séquence number(5) qui alimente un identifiant unique dans une colonne avec des valeurs allant de 1 à 99 999. Lors d'insertions, il est possible qu'il y ait des « trous de séquence » dû à une annulation ou une erreur système. Si nous voulons récupérer ces identifiants non utilisés, nous avons quelques options dont l'utilisation des ensembles.
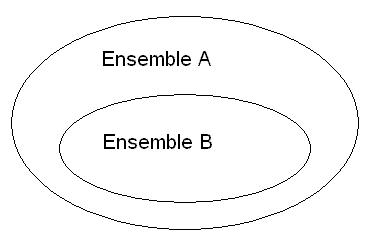
L'idée est d'utiliser les valeurs de l'ensemble A (1 à 99 999) moins les données de l'ensemble B (la plage de valeurs de notre identifiant unique allant jusqu'à 99 999). Ainsi, la résultante de cette opération sera l'ensemble des valeurs non utilisées. Dans notre exemple, nous supposons une table d'employés (EMP) avec une colonne ID comme identifiant unique.
select rownum
from all_objects
where rownum < 100000
minus
select id
from emp;Le problème avec l'utilisation d'une table bidon telle que ALL_OBJECTS est qu'on est limité par le nombre d'entrés dans la table. Si ALL_OBJECTS contient 50 000 entrés et que notre écart de valeurs se situe en-dessous de cette limite, alors nous pouvons utiliser une table de ce genre. Toutefois, si notre écart de valeurs se situe au-dessus de cette limite, nous devons trouver une autre solution. C'est dans cette optique que je suggère l'utilisation de la table DUAL avec un « connect by level < n ».
select rownum
from dual
connect by level < 100000
minus
select id
from emp;Prendre note que l'utilisation de la table DUAL avec la clause « connect by level » peut occuper un espace mémoire important dans le UGA (dans le PGA si la session est en mode dédiée ou dans le large pool en session partagée).
Commentaires